
Priv's Blog
사운드 렌더링 시스템 본문

1. 사운드 렌더링 시스템
사운드 렌더링 시스템은 비주얼 렌더링 시스템만큼이나 몰입감과 현실감에 큰 영향을 미치는 중요한 렌더링 시스템이지만, 비주얼 렌더링 시스템만큼이나 널리 확산되지는 못한 분야이다.
비주얼 렌더링 시스템보다 구현이 쉽고 비용이 저렴하다는 특징이 있지만, 그럼에도 체험자의 가상 세계 속 상호작용을 구현할 때 빼놓을 수 없는 중요한 영향력을 발휘한다.
또한 사운드 렌더링 시스템도 비주얼 렌더링 시스템과 더불어 게임 분야의 발전이 상당한 기여를 한 분야이기도 하다.
빛과 동일하게 소리(사운드)도 하나의 파장(Hz 단위)으로 구현되기 때문에 여러모로 유사한 점이 많은 특징을 띠고 있다.
소리가 어떻게 확산되는지를 시뮬레이션하기 위해서 레이 트레이싱 기술이 사용되는 것이 대표적인 예이다.
물론, 소리와 빛이 동일한 매질을 사용하는 것은 아니기 때문에 차이점도 분명하게 존재한다.
무엇보다 파장의 길이도 다르고, 속도도 다르다.
빛의 파장은 나노미터(nanometer) 단위를 사용해 계산하지만, 소리의 파장은 센티미터(centimeter) 단위를 사용한다.
또한 빛은 전자기파(electromagnetic radiation)이지만, 소리는 액체/기체/고체 등 매질의 종류가 다양하다.
마지막으로 가장 큰 특징은 빛과 달리 소리는 회절이 가능하여 발생지와 수신자 사이에 코너 또는 장애물이 있어도 소리가 줄어들거나 왜곡될 수는 있지만 전달 자체는 가능하다는 점이다.
2. 사운드 렌더링
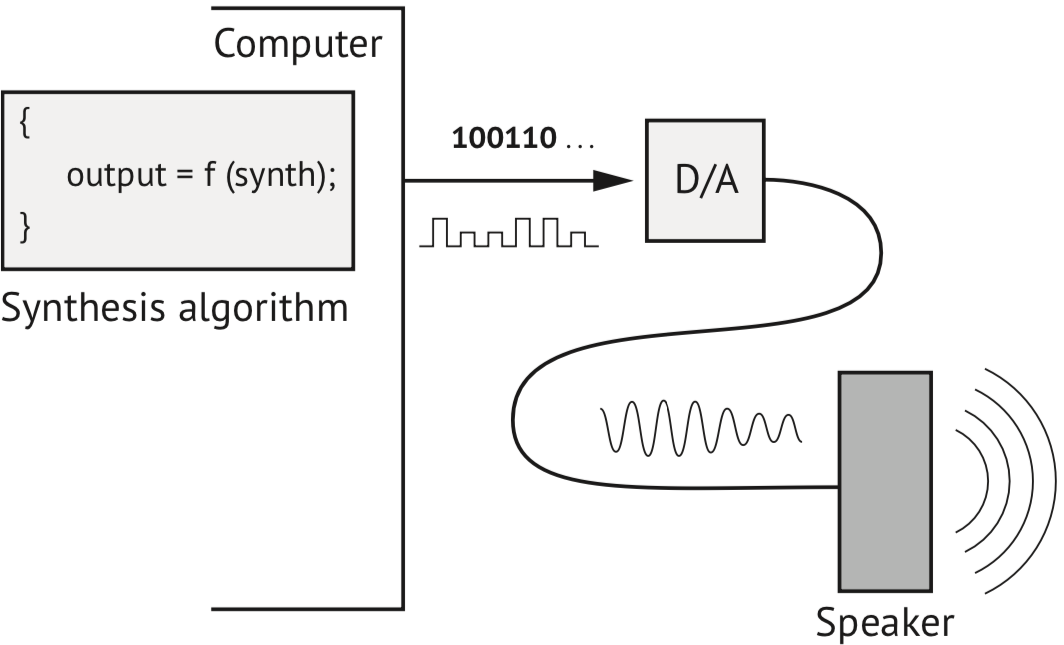
컴퓨터 시스템을 활용해 사운드를 렌더링 하기 위해서는 디지털 신호를 아날로그 신호로 변환해 주는 DAC(Digital to Analog Converter)라는 장비가 필요하다.
이는 컴퓨터는 내부적으로 데이터를 처리할 때 디지털 신호를 사용하지만, 사운드는 연속적인 파형을 가지는 아날로그 신호이기 때문이다.
이 때문에 컴퓨터에 저장된 디지털 데이터를 아날로그 형태의 소리로 변환하거나 그 반대의 과정에서 필연적인 손실이 발생할 수밖에 없다.
이러한 데이터 손실이 사운드 렌더링 품질에 미치는 영향을 최소화하기 위해, 사운드 데이터를 저장할 때는 인간의 청력으로 듣기 힘든 고주파 영역의 파장부터 우선적으로 손실되도록 하는 기법이 적용되기도 한다.
사운드 렌더링에는 아래와 같은 세 가지 주요 단계가 존재한다.
- 사운드 합성 (Sound Synthesis): 사운드를 생성하는 단계이다. 오브젝트가 어떤 상호작용을 하여 어떠한 사운드를 발생시켰는가에 따라서 생성되는 사운드는 달라진다. (그것이 무엇인가? - What is it?)
- 사운드 전파 (Sound Propagation): 생성된 사운드가 공기나 다른 매체를 통해서 전달되는 단계이다. 사운드가 전달되는 공간의 특징, 매질의 종류 등에 따라서 사운드의 특성(메아리 등)은 달라질 수 있다. (그것이 어디에 있나? - Where is it?)
- 사운드 공간화 (Sound Spatialization): 체험자가 소리의 방향성을 인지하는 단계이다. 다양한 청각적 단서와 뇌의 처리 과정이 상호작용하는 결과로 형성된다. (나는 어디에 있나? - Where am I?)
3. 사운드 렌더링 기법
사운드 또한 비주얼 렌더링 기법 때 언급했던 것처럼 실시간 연산을 통해 제작하는 실시간 렌더링 기법과 미리 연산한 데이터를 적재적소에 맞게 재활용하는 '베이킹(Baking)' 기법 모두 활용이 가능하다.
여기서 말하는 사운드 베이킹 기법도 비주얼 렌더링에서 사용된 베이킹 기법과 동일한 장단점을 지닌다.
즉, 미리 계산된 효과를 그대로 사용해도 문제가 없는 정적인 사운드에서는 효과적이지만, 실시간으로 변화하는 동적인 사운드에는 사용할 수 없다는 것이다.
3.1. 샘플링 (Sampling)
샘플링은 현실 세계에서 사운드 소스를 생성하는 가장 일반적인 방법으로, 원하는 사운드 소스를 직접 녹음하여 컴퓨터에 디지털 데이터로 변환해 저장하고, 수정하고, 재생하는 프로세스를 의미한다.
사운드는 아날로그 데이터이므로, 샘플링을 위해서는 아날로그 데이터를 디지털 데이터로 변환하는 ADC(Analog to Digital Converter)가 필요하다.
이 과정에서도 앞서 언급한 바와 같이 데이터 손실이 필연적으로 일어나게 된다.
사운드 샘플을 녹음할 때 주의해야 할 점은 사운드를 녹음하는 현실 세계의 환경이 사운드 샘플에 영향을 미친다는 것이다.
즉, 주변 사람들의 말소리나 소음이 사운드 샘플에 섞일 수도 있으며, (의도하지 않게) 메아리가 치는 효과가 녹음될 수도 있다는 것이다.
이러한 영향을 최소화하기 위해서 방음 시설이 갖추어진 스튜디오나 무향실에서 녹음을 진행하는 것이 가장 좋지만, 의도적으로 이러한 효과를 추가할 수도 있다.
이와 같이 자연적, 인위적인 소리가 완전히 제거된 환경에서 오로지 원본 사운드만 녹음된 경우, 이를 드라이 사운드(Dry Sound라고 부른다.
반대로 자연적, 인위적인 소리 등 공간의 특성이 반영된 사운드는 웨트 사운드(Wet Sound)라고 부른다.
3.2. 사운드 합성 (Synthesis)
사운드 합성 기법은 실시간 렌더링 기법처럼 컴퓨터가 가지고 있는 사운드 합성 알고리즘에 따라 유연하게 사운드를 합성하여 제작해 사용하는 기법이다.
샘플링 기법보다 컴퓨터 연산 자원에 대한 부담은 커지지만, 개발자가 원하는 어떠한 사운드도 마음대로 제작하는 것이 가능하기 때문에 자유도가 대폭 커지게 된다.
사운드 합성 기법에는 아래와 같이 세 가지 하위 카테고리가 존재한다.
- 스펙트럴 합성 기법
- 물리적 사운드 합성 모델
- 추상적 사운드 합성
이와 별개로 사운드 합성 기법만으로 풍부하고 현실적인 복잡한 사운드를 제작하는 것은 상당히 어려운 일이다.
서로 다른 파형을 지닌 사운드끼리 충돌하게 되면 두 파형이 융합되어 새로운 사운드가 형성되거나 상쇄되어 사운드가 사라지는 것도 가능하다.
이는 즉, 다양하게 섞여있는 사운드를 개별 사운드로 분리한다는 것은 사실상 불가능에 가깝다는 것을 의미한다.
그러므로 복잡한 사운드를 합성하고 싶다면 먼저 독립적인 사운드를 각각 준비한 다음, 이들을 합성하는 과정을 거쳐야 한다.
또한 현실적인 사운드는 실시간으로 톤이 변하는 매우 동적인 특성을 지니고 있다.
이러한 변화까지 정확하게 구현하기 위해서는 시간과 공간의 변화에 따른 파형의 변형까지 함께 고려해야 할 것이다.
3.2.1. 스펙트럴 합성 기법 (Spectral Synthesis Methods)
스펙트럴 합성 기법은 사운드 주파수의 스펙트럼을 분석하고 이를 재구성하여 원본 사운드를 재구성하는 기법이다.
즉, 컴퓨터에 저장되어 있는 사운드에 대한 (디지털) 데이터(주파수, 진폭 등)를 분석하여 원래 소리(아날로그)를 재구성하는 기법이다.
스펙트럼 분석에는 시간이나 공간에 대한 함수를 시간이나 공간에 대한 주파수 성분으로 변환해 주는 '푸리에 변환' 기법이 사용된다.
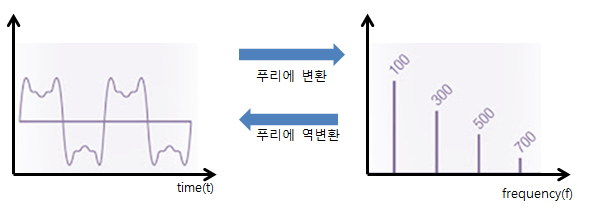
즉, 사운드를 푸리에 변환 함수에 넣게 되면 각 주파수 성분(진폭 등)을 파악할 수 있게 되므로, 이렇게 파악한 주파수 성분을 디지털 데이터로 컴퓨터에 저장했다가 소리로 재구성할 때는 '역푸리에 변환' 기법을 적용하는 것이다.
3.2.2. 물리적 사운드 합성 모델
물리적 사운드 합성 모델은 물리 법칙에 근거하여 사운드를 합성하는 기법이다.
두 오브젝트의 충돌에 의한 소리, 공기의 흐름에 의한 바람 소리, 폭포가 떨어지는 소리 등 물리적인 현상에 의해서 발생하는 소리를 구현하기 위해 사용된다.
가상 세계 속 상호작용에 대한 현실감을 높이는데 특히 중요한 역할을 수행한다.
다만 물리적 현상에 의한 시뮬레이션 연산이 요구되기 때문에 사운드 합성을 위해 얼마나 많은 계산이 요구되며, 그렇게 증가된 렌더링 비용이 얼마나 값어치가 있는지를 최대한 정확하게 판단하여 활용해야 그 효과를 극대화할 수 있다.
3.2.3. 추상적 사운드 합성
추상적 사운드 합성 기법은 어떠한 시스템에 의해서 생성된 숫자의 스트림을 기반으로 소리를 제작하고, 주어진 함수에 따라서 음파를 형성하는 합성 기법이다.
이는 현실 세계 속에 있는 어떠한 소리를 재구성하는 것이 아니라, 자연환경 속에 존재하지 않는 소리를 창조하기 위해 사용된다.
즉, 이 기법은 수학적 데이터와 계산 결과를 통해서 사용자에게 소리로 위험 경보를 전달하거나, 값의 변화를 소리로 표현하는 등 전달해야 하는 정보를 청각적으로 전달하는 것에 의미를 두고 있다.
3.3. 사운드 필터링
필터는 사운드 분야에서 널리 활용되는 기술 중 하나로, 사운드의 진폭을 의도적으로 키우거나 줄이기 위해 사용된다.
일반적으로 흔히 사용되는 필터로는 다음과 같다.
- 로우 패스 필터(Low-pass filter): 고주파를 걸러내고 저주파 사운드만 통과하도록 하는 필터
- 하이 패스 필터(High-pass filter): 저주파를 걸러내고 고주파 사운드만 통과하도록 하는 필터
- 밴드 패스 필터(Band pass filter): 정의해 둔 특정 영역대의 파장만 통과하도록 하는 필터
사운드 필터를 활용하면 보다 현실감 있는 사운드 효과를 구현할 수 있다.
예를 들어 소리가 멀어질수록 고주파가 감쇠되는 효과를 가상 세계 속에서 구현하고자 한다면 거리에 따라 로우 패스 필터를 강하게 적용하면 될 것이다.
3.3.1. 콘벌루션 필터 (Convolution Filter)
콘벌루션 필터는 수학적 연산을 파형에 적용하여 다양한 방식으로 사운드를 필터링하는 기법이다.
예를 들어 소리가 반사되어 메아리치는 듯한 효과(Reverberation)나 특정한 위치에서 소리가 발생하는 것처럼 들리게 만드는 효과를 구현하고 싶을 때 콘벌루션 필터를 사용할 수 있다.
사운드를 변형하는 데 활용할 수 있는 프로파일인 임펄스 응답(Impulse Response)을 콘벌루션 필터에 적용해 사용하면 미리 정의된 특정 환경에서의 소리 변화 효과를 추가할 수 있다.
임펄스 응답은 짧고 강렬한 소리(총소리, 버튼 클릭 소리 등)로 만들어진 임펄스 사운드(Impulse Sound)를 통해 제작된다.
임펄스 사운드는 체험자가 위치할 것이라고 예상되는 가상 세계 속 환경과 유사한 공간에서 사운드를 연출해 녹음하는 방식으로 제작되며, 임펄스 응답은 본질적으로 수학적인 계산을 기반으로 하고 있기 때문에 임펄스 사운드만 입력된다면 자신이 원하는 데로 필터링을 적용해 결과물을 제작할 수 있다.
3.4. 사운드의 전파
사운드가 생성되면 장애물과 공간의 특성에 따라 산란, 통과, 반사되면서 공간 속을 이동하며 확산된다.
사운드가 이동, 확산되는 경로를 추적해 보면 사운드가 발생한 공간의 주변 특성과 발생 원인, 위치 등을 추측할 수 있게 된다.
사운드가 전파되는 효과를 연산하고, 상황에 따라 인간이 인지하는 음향 환경, 즉 '소리의 풍경화'를 구현하는 것을 사운드스케이프(Soundscpae)라고 부른다.
자연적인 소리부터 인위적인 소리까지 체험자가 위치한 장소와 주변 환경의 특징에 따라 발생하는 수많은 크고 작은 소리(일종의 소음)를 구현하여 사운드를 통해 공간감과 현실감을 강화하는 것이다.
사운드의 전파 범위와 거리 등은 주파수의 특징에 영향을 받는다.
고주파는 직진성이 강하고 회절성이 약하기 때문에 장애물이나 코너 등이 많은 공간에서는 전파 범위가 좁아지며, 전파 거리도 상대적으로 짧다.
반대로 저주파는 직진성이 약하고 회절성이 강하기 때문에 장애물이나 코너 등에도 큰 영향을 받지 않으며, 전파 거리가 상대적으로 길다.
사운드 전파를 기하학적 연산법으로 다룰 때는 사운드를 파동보다는 하나의 입자로 취급하여 그 입자들이 공간 안에서 어떻게 움직이는지를 계산한다.
이 때문에 사운드의 움직임을 연산하기 위해 레이 트레이싱 기법이나 빔 트래킹 기법이 사용되기도 하며, 이러한 방법은 앞서 언급한 것처럼 직진성이 강한 고주파 사운드를 다룰 때 효과가 크다.
4. 복잡한 사운드 렌더링 방법
사운드는 그 자체로 복잡할뿐더러 역동적이기 때문에 현실감 있는 사운드를 렌더링 하는 효과적인 방법을 개발하는 건 상당히 어렵다.
하나의 단순한 폴리곤을 보는 것이 지루한 것처럼 사인파 하나만 사용한 단순한 사운드는 체험자를 짜증 나게 만들 것이다.
사운드는 순간적이고 연속적이기 때문에 시간 경과에 맞춰 매우 빠른 렌더링 속도로 제작되어야 하며, 인간의 귀와 뇌는 사운드 파형에 생기는 약간의 변화도 구별할 수 있기 때문에 미묘한 느낌과 차이, 디테일을 엄격하게 관리해야 한다.
당연하지만 사운드도 단순하면 단순할수록 렌더링 속도는 빨라지며, 더 많은 리소스를 활용해 복잡한 사운드가 만들어지면 렌더링 속도는 그만큼 느려지게 된다.
이 때문에 개발자는 비주얼 렌더링 기법에서 사용된 LOD, 컬링, 텍스처 매핑 기법 등과 같이 다양한 '트릭'을 활용해 연산 부담과 퀄리티 사이의 적합한 밸런스를 맞출 수 있어야 한다.
4.1. 주파수 변조 (FM)
라디오를 쓸 때 쉽게 볼 수 있는 '주파수 변조' 기법은 사운드의 스펙트럼 생성 방법 중 하나로, 소리의 진폭은 일정하게 유지한 채 주파수를 조작하여 사운드를 내는 기법이다.
진폭 변조(AM) 기법보다 음질이 좋고 잡음이 적다는 장점이 있지만, 변조한 파의 진동수 변화 범위가 넓어져서 광대역의 주파수(고주파)를 요구하기 때문에 상대적으로 전파 범위가 좁다.
4.2. 가산 합성과 감산 합성
가산 합성 기법은 사인파를 더해서(가산) 음색을 만들어내는 사운드 합성 기법이다.
즉, 다양한 주파수 신호를 결합하여 원하는 사운드를 생성하는 것이다.
감산 합성 기법은 필터링을 활용해 사인파의 일부분을 조작(감산)하여 음색을 만들어내는 사운드 합성 기법이다.
사운드도 파장이기 때문에 두 가지 이상의 사인파를 어떻게 결합하느냐에 따라서 파장이 증폭되거나 상쇄되는 특징이 있다.
이러한 특징을 활용하면 완전히 반대되는 형태의 사인파 두 개를 결합하여 아예 사운드가 들리지 않게 만드는 것도 가능하다. (가산 기법)
이를 좀 더 응용해 보면 특정한 패턴을 지닌 사운드만 따로 분석하여 반대되는 사인파를 만들어 필터링을 적용하는 방식으로 소음을 제거하는 '노이즈 캔슬링'이 탄생한다.
가산 합성과 감산 합성 기법에는 '푸리에 분석'이라는 수학적 기법이 주축이 된다.
푸리에 분석은 앞서 언급한 것처럼 복잡한 파형을 구성하고 있는 개별 사인파를 분석하는 수학적 기법으로, 사인파의 주파수, 진폭, 위상을 결정할 수 있게 해 준다.
4.3. 그래뉼러 합성법
그래뉼러 합성법은 비교적 최근에 개발된 사운드 합성법으로, 음원을 매우 짧은 시간 단위로 쪼개서 하나의 '조각'을 만들고, 이 조각들을 일정한 규칙에 맞게 재구성하여 새로운 소리를 만들어내는 기법이다.
이렇게 재구성되는 사운드는 사용된 규칙에 따라서 완전히 다른 음색을 가질 수 있기 때문에 개발자가 원하는 새로운 음색을 자유롭게 제작하는 것이 가능하다.
예를 들어, 물 한 방울이 바위 위에 떨어지는 소리에 그래뉼러 합성법을 적용하게 되면, 그 소리를 조각으로 쪼개어서 재구성하면 폭포수가 떨어지는 소리를 재현할 수 있다는 것이다.
4.4. 코러싱 (Chorusing)
코러싱은 실존하는 신호를 프로세싱하여 새로운 사운드를 생성하는 기법이다.
주파수 변조, 위상 변조 등 원본 사운드에 (조미료를 가하듯이) '믹싱(Mixing)'하여 새로운 사운드를 만드는 것이다.
4.5. 모달 분석
현실 세계에서 사물끼리 상호작용하게 되면 그에 따른 힘이 발생하며, 그 힘이 사물 주변을 둘러싸고 있는 공기를 진동시켜서 소리를 발생시킨다.
모든 단단한 사물은 종류와 충돌 강도 및 조건 등에 따라 낼 수 있는 사운드의 공명 주파수가 존재한다.
즉, 사물에 충격이 가해지면 충격 에너지가 사물을 통과하며 변형을 일으켜 사물의 표면이 진동하게 되고 그 진동이 음파를 발산한다는 것이다.
하지만 가상 세계에 존재하는 사물들은 물리적인 충돌을 시뮬레이션하기 위해서 강체(Rigidbody)로 취급된다.
즉, 충돌이 발생해도 변형되지 않는 존재로 취급된다는 것이다.
이는 다시 말해서 아무리 충돌이 발생해도 현실 세계와 달리 변형이나 진동이 생기지 않으므로 음파가 발산될 수 없다는 것을 의미한다.
결국 컴퓨터의 연산을 통해 물리적 상호작용에 따른 사운드를 구현하는 것은 우리를 속이는 것에 불과하다.
사물에 충격이 가해지거나 악기의 현을 당기는 것처럼 어떠한 상호작용에 의해서 진동이 발생했는지를 알 수 있다면, 사운드 렌더링 과정에서 사용할 파형을 시뮬레이션하여 제작하는 것이 가능하다.
만약 악기의 현, 원통형 튜브처럼 사물의 형태가 단순하다면 연산도 단순해지기 때문에 정확한 시뮬레이션이 가능하겠지만, 형태가 복잡한 사물의 경우에는 그렇지 않다.
그러므로 복잡한 사물의 형태를 시뮬레이션에 용이한 형태로 먼저 단순화시킨 뒤, 해당 사물이 지니는 고유한 진동 특성을 미리 계산하여 시뮬레이션에 활용하는 것이 더 현실적일 것이다.
모달 분석은 이러한 사물의 변형 모드(물체가 외부의 힘을 받을 때 나타나는 고유의 진동 형태나 모양)를 계산하는 작업이다.
모달 분석 작업은 가상 세계를 실시간으로 시뮬레이션하기 전에 미리 수행되며, 모달 분석 작업의 결과물은 이후 사물 간의 상호작용 발생에 따른 사운드 시뮬레이션 작업을 수행할 때 매개변수로써 활용된다.
4.6. 전파(Propagation) 및 환경 효과
사운드를 렌더링 할 때 렌더링 시간에 제약이 없다면, 수백 번이 넘는 반사도, 사운드의 경로에 대한 다양한 효과(반사, 굴절, 확산, 산란 등)도 계산할 수 있어 매우 현실적인 사운드를 제작할 수 있을 것이다.
하지만 실시간으로 처리해야 하는 분야에서는 현실적으로 이 정도로 현실적인 사운드를 제작한다는 것은 거의 불가능하다.
무엇보다 첫 80ms 이후부터는 실내에서 발생한 모든 상호작용이 만들어내는 사운드는 동일하게 처리하므로, 그때부터는 더 이상 소리의 발생 근원지는 중요한 요소가 되지 못한다.
그러므로 사운드 이벤트에서 지각되는 사운드는 아래와 같이 세 가지 요소로 구성되며, 이는 각각 렌더링의 세 가지 단계와 매칭된다.
- 드라이 사운드 (Dry Sound): 드라이 사운드는 소리가 생성되어 청취자에게 도달하는 '직접음'을 의미한다. 즉, 반사나 흡수 등 어떠한 효과를 받지 않고 소리의 원천이 직접적으로 청취자에게 곧장 전달되는 것이다. 이러한 특징 때문에 청취차가 소리의 방향성을 인지하는 데 가장 중요한 역할을 한다.
- 초기 반사음 (Early Reflection): 초기 반사음은 소리가 발생한 지 80ms 이내에 도달하는 반사음이다. 소리가 표면에 반사된 뒤 짧은 시간 안에 청취자에게 도달하는 소리를 의미한다. 공간의 물리적 특징을 청취자에게 전달할 수 있으며, 드라이 사운드와 함께 공간감 및 소리의 방향감을 강화시키는 역할을 한다.
- 잔향음 (Late Reflection): 초기 반사음 이후에 여러 번의 반사를 거쳐서 80ms 이후에 청취자에게 도달하는 반사음이다. 공간 전체에서 발생하는 복잡한 반사로 인해 더 길고 지속적이며, 소리 근원지에 대한 정보는 거의 잃어버린다. 그 대신 소리의 부드러움과 풍부함을 더해주는 역할을 한다.
4.6.1. 적응형 직교 분해법 (Adaptive Rectangular Decomposition)
적응형 직교 분해법은 주어진 데이터, 신호를 특정 기준에 따라 사각형 영역으로 분해하여 처리하는 기법을 말한다.
꼭 사운드 분야에서만 쓰이는 것은 아니며, 영상 처리나 신호 분석, 빅데이터 처리 등 다양한 분야에서 활용되는 기법이다.
데이터를 고정된 방식으로 분해하는 대신, 데이터의 특성에 따라서 분해 크기나 위치를 동적으로 조정하는 방법을 사용한다.
데이터를 분해할 때는 사각형 또는 직교 형태의 영역으로 나누게 되는데, 이는 보다 효율적인 계산을 가능하게 하기 위함이다.
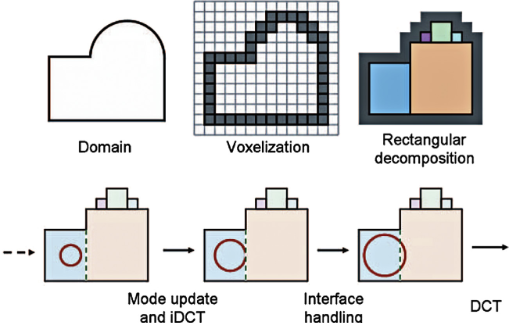
정확도 손실을 최소화하기 위해서 처음에는 가장 큰 직교 형태로 먼저 나누었다가, 이를 점차 더 작은 형태로 쪼개어 나가는 작업도 함께 수행된다.
이름대로 '적응형'이기 때문에 데이터의 특성에 따라서 분해를 조정함으로써 메모리 사용량 및 연산 부담을 최적화할 수 있고, 불필요한 세부 정보를 줄이고 중요한 특징을 강조할 수 있다는 것이 특징이다.
4.6.2. 로컬라이제이션과 공간화
앞서 언급한 것처럼 인간은 사운드의 특성을 통해서 사운드가 발생한 방향, 공간의 특징 등을 추측할 수 있다.
인간의 지각 능력이 사운드를 통한 공간 및 방향 감지에 영향을 미치는 것처럼 사운드 그 자체에 대한 특성과 효과도 방향과 거리 감지에 영향을 미친다.
사운드가 나는 방향과 거리를 감지할 때 영향을 미치는 기본적인 효과들은 아래와 같다.
- 사운드 감쇠: 거리에 따라 사운드의 볼륨 차이
- ILD (Interaural Level Difference): 어느 쪽 귀가 사운드를 더 크게 듣는가?
- ITD (Interaoural Time Difference): 어느 쪽 귀가 사운드를 먼저 듣는가?
ILD와 ITD에 영향을 미치는 것은 사운드의 파장이다.
ITD는 머리보다 작은 파장의 소리에서 더 많은 단서를 얻게 되므로 지각이 쉬워질 것이며, 반대로 ILD는 머리보다 큰 파장의 소리에서 더 많은 단서를 얻게 될 것이다.
공간화 사운드를 제공하는 가장 쉬운 방법이 이러한 효과를 활용하는 것이다.
머리를 기준으로 오브젝트의 좌/우 위치를 파악하고 스테레오 음원의 좌/우 볼륨을 조절하여 음원과 체험자 머리 사이의 거리에 따른 딜레이를 재현하는 것이다.
소리의 근원지가 체험자 머리 기준 우측에 있다면, 사운드 볼륨을 조정할 때 왼쪽보다 오른쪽을 더 크게 하고, 왼쪽 사운드의 딜레이를 오른쪽보다 강하게 하여 오른쪽 귀가 왼쪽 귀보다 소리를 더 크고 먼저 듣게 만드는 것이다.
이렇게 되면 체험자는 ILD와 ITD를 통해 사물이 오른쪽에 있을 것이라 추측하게 된다.
동일한 소리를 전방위에서 발생시켜서 방향에 따른 주파수 반응을 측정하여 3차원 함수로 정리한 것을 머리전달함수(Head Related Transfer Function)이라고 부른다.
즉, HRTF는 사람의 머리, 귀, 어때 등 체험자의 신체가 소리를 왜곡하는 방식을 수학적으로 나타낸 함수이다.
이 함수는 특정 방향에서 오는 소리가 귀에 도달할 때까지 발생하는 주파수 왜곡, 시간 차이를 모델링하는 것으로, 인간이 소리의 방향과 거리를 인식하는 데 중요한 역할을 한다.
마지막으로 사운드 스테이지(Sound Stage)는 무대나 공연장 같은 곳에서 소리가 재생될 때, 청취자가 느끼는 가상의 음향 공간, 소리의 무대감을 의미한다.
다만, 사운드 스테이지를 사용하게 되면 체험자가 고개를 돌리거나 다른 곳으로 움직이게 되면 몰입감이 무너지게 되므로, 의자에 앉아있는 극장처럼 체험자가 움직이지 않고 고정된 장소에 머무른다는 조건 하에 활용해야 그 효과를 볼 수 있다.
5. 사운드 렌더링 프로세스
5.1. 사운드 렌더링용 하드웨어
작곡 소프트웨어, 신시사이저 등과 같이 사운드 렌더링에 사용되는 전문 장비는 소프트웨어와 하드웨어 분야 모두에 널리 퍼져있다.
대부분의 사운드 제작 장비는 음악을 제작하는 것에 초점을 맞추고 있으며, 이러한 장비들은 대부분 음악 분야에서 사용되는 음고(pitch)를 통해 사운드를 다룬다.
다양한 비음악적인 효과음(파도 소리, 바람 소리, 엔진 소리 등)을 다루는 사운드 장비도 존재한다.
이러한 사운드는 소리의 생성과 확산 등을 시뮬레이션하여 제작하기도 하며, 연출된 환경에서 미리 녹음된 사운드에 별도의 필터나 효과를 입혀서 완성하기도 한다.
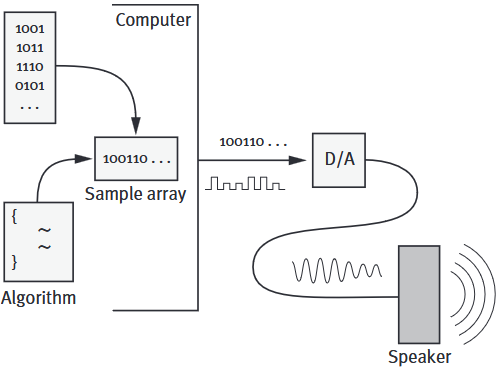
사운드를 컴퓨터 장비에 저장/재생/조작하는 과정은 사운드라는 아날로그 신호를 디지털 신호로 변환하여 저장(ADC)하고, 저장된 디지털 신호를 아날로그 신호로 변환하여 재생(DAC)하는 단계로 진행된다.
현대에 사용되는 거의 모든 컴퓨터 장치(노트북, 데스크톱, 스마트폰, 태블릿 PC 등)는 사운드의 출력과 저장은 물론, 다양한 소프트웨어를 통해서 사운드에 필터를 입히는 등의 조작도 가능하다.

이러한 범용성은 디지털 신호 처리 장치(Digital Signal Processor)라는 마이크로프로세서의 보급 덕분이다.
해당 프로세서는 디지털 신호 처리를 빠르고 효율적으로 처리하기 위해 제작된 별도의 칩셋으로, DAC와 ADC 두 가지 역할을 모두 수행한다.
대부분의 사운드 렌더링 하드웨어/소프트웨어의 수요는 전문적으로 사운드 렌더링 분야를 다루어야 하는 방송/영화/광고/음악 산업이 주를 이루고 있어 해당 분야에 특화된 기능과 요구사항에 최적화되어 있다.
이는 전문적인 특정 분야에서의 활용이 주를 이룬다는 것을 의미하기 때문에 해당 소프트웨어/하드웨어의 가격과 접근성에 있어서 부담이 매우 높다는 것을 의미하기도 한다.
전문적인 사운드 렌더링 시스템은 작동부터 제어까지 다양한 기술 및 준비 과정, 비용 등이 요구될뿐더러 시스템을 사용하지 않는 동안에도 상당한 비용이 소모된다.
VR 시스템 분야에서도 이러한 이유 때문에 일반적인 가정이나 사무실 등에서 사용되는 경우에는 대부분 범용 컴퓨터 장비에서 구동되는 소프트웨어 기반의 사운드 렌더링 시스템을 활용하고 있다.
그럼에도 제한적으로 전문적인 사운드 렌더링 하드웨어 시스템이 도입된 경우에는 높은 수준의 사운드 렌더링 성능이 요구되는 첨단 기술 기반의 훈련/교육 장소일 가능성이 높다.
5.1.1. 전문 사운드 렌더러 (사운드 신시사이저)
사운드 제작을 위한 특수한 하드웨어와 하나 이상의 알고리즘을 활용해 사운드를 제작하는 장비.
피치, 볼륨, 음색과 같은 다양한 매개변수를 조정하여 합성된 사운드를 제작할 수 있다.
대부분 위 사진과 같이 키보드 건반처럼 생긴 모습에 다양한 노브 등이 부착된 형태를 띠고 있으며, 특정 악기의 소리를 묘사하기 위해 사용된다.
5.1.2. 범용 사운드 렌더러 (프로그래밍 가능한 사운드 프로세서)
저장된 사운드를 재생하는 것 대신, 사운드를 연산하는 장비.
위 사진과 같은 DSP 엔진을 활용한 소프트웨어로 사운드를 프로그래밍하여 생성/재생한다.
5.1.3. 사운드 포스트 프로세서
서로 다른 청취 환경, 공간 음향(3D 사운드)을 구현하기 위해 다양한 특수 효과를 적용하는 장비.
이 또한 DSP를 사용하며, DSP 엔진을 활용한 소프트웨어나 상용 DSP 장비를 활용해 구현된다.
일반적으로 MIDI(Musical Instrument Digital Interface) 또는 다른 통신 인터페이스를 활용해 특수 효과를 구현하는 매개변수 제어가 가능하다.
5.2. 사운드 애셋 인코딩
사운드를 표현하기 위해서 물리적으로 시뮬레이션하는 것이 가장 이상적이라고 생각하기 쉽지만 마냥 그렇지만은 않다.
사운드를 표현할 때도 연산 비용과 퀄리티 사이의 타협이 필요하다.
즉, 결국은 다른 렌더링 분야와 마찬가지로 사운드 렌더링 또한 "얼마나 실용적인가?"를 따져야 한다는 것이다.
사운드를 시뮬레이션해서 연산할 것인지, 미리 녹음된 사운드를 재생만 할 것인지, 녹음된 사운드를 공간에 따른 효과를 적용해 합성하거나 필터링하여 사용할 것인지 상황과 여건에 맞게 렌더링 방법을 적절하게 선택하는 것이 중요하다.
사운드 또한 비주얼 이미지와 마찬가지로 사운드 파형은 여러 숫자의 모음으로 구성된다.
사운드 데이터에서 사용되는 프레임 레이트는 '샘플 레이트(Sample Rate)'라고 불리는데, 저장 매체의 종류에 따라서 샘플 레이트 값은 조금씩 달라진다.
CD는 44,100Hz를 사용해 스테레오 사운드를 표현하며, DVD는 96,000Hz까지 사용하기도 한다.
각 숫자를 나타낼 때 사용되는 비트 수도 사운드 데이터의 품질에 영향을 미친다.
16bit는 심포니홀에서 연주하는 오케스트라 음질을 커버할 수 있는 수준이며, 저품질 오디오는 8bit를 사용하기도 한다.
이와 더불어 사운드 파일을 저장할 때 사용되는 포맷의 종류에 따라 샘플 레이트, 비트 수, 채널 수, 압축 알고리즘이 달라진다.
일부 포맷은 특정 값만 지원하도록 디자인되어 있으며, 심지어 컴퓨터의 운영체제에 따라서도 지원하는 포맷이 달라지기도 한다. (WAV, AIFF 등)
최종적으로 청취자가 듣게 되는 사운드는 엔지니어링 과정을 거쳐서 사운드 디자이너의 의도대로 다양한 효과와 필터가 적용된 웨트 사운드(Wet Sound)에 해당한다.
VR 경험과 같은 인터렉티브 가상 환경에서는 사운드 파형을 통합하기 위해 사운드 클립 외에 별도의 음향 특성이 최소화된 드라이 사운드(Dry Sound)를 선호하는 경향이 있다.
앞에서 잠깐 언급된 MIDI 포맷은 전자 악기와 컴퓨터 사이의 통신을 위해 사용되는 표준 프로토콜이다.
이 포맷은 악보에 있는 일련의 액션, 이벤트 등을 담아낸다.
일반적으로 MIDI 포맷은 상업용 음악 신시사이저 또는 오디오 신호에 다양한 효과를 추가하는 포스트 프로세서 장치로 전송된다.
MIDI를 사용하면 신시사이저 안에서 실제 사운드가 생성되고, 포스트 프로세서로 전송된 MIDI 명령은 잔향, 코러싱, 디스토션, 볼륨 등 다양한 매개변수 설정을 제어하는 데 사용된다.
5.3. VR 사운드 렌더링 소프트웨어
VR 시스템에서 사용되는 사운드 렌더링 소프트웨어는 비주얼 렌더링 소프트웨어와 마찬가지로 게임 엔진과 많은 연관성이 있다.
게임 엔진을 VR 인터페이스용 가상 세계 렌더링에 활용하는 사례가 증가하면서 사운드 렌더링 방법에 다양한 변화가 생겨난 것인데, 그러한 움직임이 나타나기 이전 세대에서의 사운드 렌더링 소프트웨어는 그저 단순한 API 형태에 불과했다.
게임 속 가상 현실의 모습을 최대한 현실적으로 만들기 위해 비주얼 렌더링과 마찬가지로 사운드 필터, 볼륨, 공간화, 코러싱 등 사운드 현실성 향상을 위한 수많은 기술들이 동원되었다.
이러한 기술들이 발전함과 동시에 전문적인 프로그래밍 능력이 없어도 사운드 현실성을 보다 쉽고 빠르게 끌어올릴 수 있도록(생산성을 높일 수 있도록) 일종의 '완성된 형태'의 사운드 렌더링 소프트웨어가 점차 등장하기 시작한 것이다.
현재는 nVidia 사의 VRWorks-Audio 또는 Valve 사의 Steam-Audio처럼 공간화, 사운드 전파 효과를 포함하여 가상 공간 내에서의 현실감 향상에 특화된 오디오 렌더러도 다수 존재하며, HMD 기기의 머리 추적 정보를 활용해 공간감을 강화하는 기능도 활용되고 있다.
GTC에서 공개된 VR웍스 오디오 및 360 비디오 SDK로 더욱 실감나는 VR 개발 전망 - NVIDIA Blog Korea
엔비디아가 현지시간 5월 8일부터 미국 캘리포니아 산호세 맥에너리 컨벤션센터에서 개최되고 있는 GPU 테크놀로지 컨퍼런스(GPU Technology Conference, 이하 GTC)에서VR 오디오 및 360도 동영상 스티칭(vi
blogs.nvidia.co.kr
앞에서 언급된 두 제품 모두 독립형 API 라이브러리를 제공하고 있어서 Unity 엔진이나 Unreal 엔진과 같은 다양한 외부 툴과 함께 활용하는 것이 가능하다.
대부분의 사운드 렌더링 API는 게임 엔진에 초점을 맞추는 경향이 있는데, 이는 당연하게도 게임 업계가 해당 분야의 주 고객층이기 때문이다.
엠비언트 사운드를 만들거나 SFX(Sound Effects)를 제작하기 위한 사운드 툴로는 Max/MSP, Pure Data, ChucK 등이 있다.
수고하셨습니다!
'Dev. Study Note > VR Introduction' 카테고리의 다른 글
| 기타 감각 렌더링 시스템 (0) | 2025.01.21 |
|---|---|
| 촉각 렌더링 시스템 (0) | 2025.01.21 |
| 비주얼 렌더링 시스템 (0) | 2025.01.15 |
| 렌더링 시스템 (0) | 2025.01.12 |
| 가상 세계의 기타 감각 표현 (0) | 2025.01.11 |



